
If you’ve ever built a backend system with database transactions, you know the promise: atomicity, consistency, and reliability. But what happens when the very mechanism meant to protect your data becomes the source of chaos? Let me take you through a real debugging nightmare I faced and how it turned into one of the most valuable lessons in backend performance issues I’ve ever learned.
Everything Was Working Perfectly
I was working on a CMS system that allowed users to define their own custom schemas. One of the field types within these schemas could be a JSON RTE (Rich Text Editor) field, which allowed authors to store structured content blocks like paragraphs, images, or embedded media.
When creating new entries for a schema, the JSON RTE content was stored in a separate MongoDB collection. This separation allowed us to efficiently manage, version, and reuse content blocks independently of the main entry data.
To ensure data consistency, I wrapped the insert operations for both the entry and its associated content blocks in a multi-document transaction using MongoDB’s startSession and withTransaction. This way, either both the entry and its content blocks would commit successfully, or neither would, preventing partial or inconsistent data from being saved.
Here’s a simplified version of what a typical entry with JSON RTE content looked like:
{
"entry": {
"title": "How to Debug Infinite Transactions",
"author": "Hitesh Shetty",
"publishedAt": "2025-09-20T10:00:00Z",
"content": {
"uid": "123",
"type": "doc",
"attrs": {},
"children": [
{
"uid": "456",
"attrs": {},
"type": "paragraph",
"text": "Transactions are great until they loop forever..."
},
{
"uid": "789",
"attrs": {},
"type": "paragraph",
"text": "Load testing revealed unexpected behavior in my backend."
}
]
}
}
}Everything worked perfectly during normal testing. Each block had a unique uid, and transactions committed reliably until load testing revealed a hidden problem.
Load Testing Reveals the Monster
Load testing is supposed to be our friend. It shows us how systems behave under stress before real users ever see them. But in this case, it revealed a nightmare.
CPU usage on my server hovered around 12%, while the database was burning at 99%. Requests that normally took milliseconds were timing out. It felt like the backend had developed a life of its own.
Half a day was spent retracing every function, every transaction, and every database call. You could feel the frustration building, even though everything appeared normal.
How Monitoring Revealed the Problem
I used Datadog to check the logs, metrics, and traces. Soon, I noticed that some functions were being called more than once for the same data.
After digging deeper with detailed logging, the culprit became clear: duplicate UIDs in the JSON RTE content.
{
"entry": {
"title": "How to Debug Infinite Transactions",
"author": "Hitesh Shetty",
"publishedAt": "2025-09-20T10:00:00Z",
"content": {
"uid": "123",
"type": "doc",
"attrs": {},
"children": [
{ "uid": "456", "type": "paragraph", "text": "Transactions are great until they loop forever..." },
{ "uid": "456", "type": "paragraph", "text": "Load testing revealed unexpected behavior in my backend." }
]
}
}
}The duplicate IDs happened because I manually created a blog session with blocks that unintentionally reused UIDs, and the API didn’t block it.
Duplicate uids made the RTE collection insertion fail. withTransaction retried automatically, and without a defined max retry count, this led to infinite retries during insertion failures. Each retry used more CPU and database resources, which quickly became a big problem. This issue did not show up in normal testing because duplicate IDs were rare and only appeared in my load-testing data.
How Duplicate IDs Triggered an Infinite Retry Loop
Here’s the breakdown:
-
Duplicate IDs in load-testing data caused failed insertions.
-
Automatic Transaction Retries by the MongoDB Driver
The Node MongoDB driver handles transactions via
startSession+withTransaction. By default,withTransactionwill automatically retry until either:- the transaction succeeds, or
- the 120-second timeout is reached.
(For reference, here's the
withTransactionsource code). -
Resource exhaustion: high DB CPU, slower responses, eventual request timeouts. This is a result of the infinite retry loop.
In short, the backend turned into a self-replicating performance problem. All of this happened because a simple edge case was missed.
Fixing the Infinite Loop with Retry Limits
The fix involved two key strategies:
1. Enforcing Max Retry Count
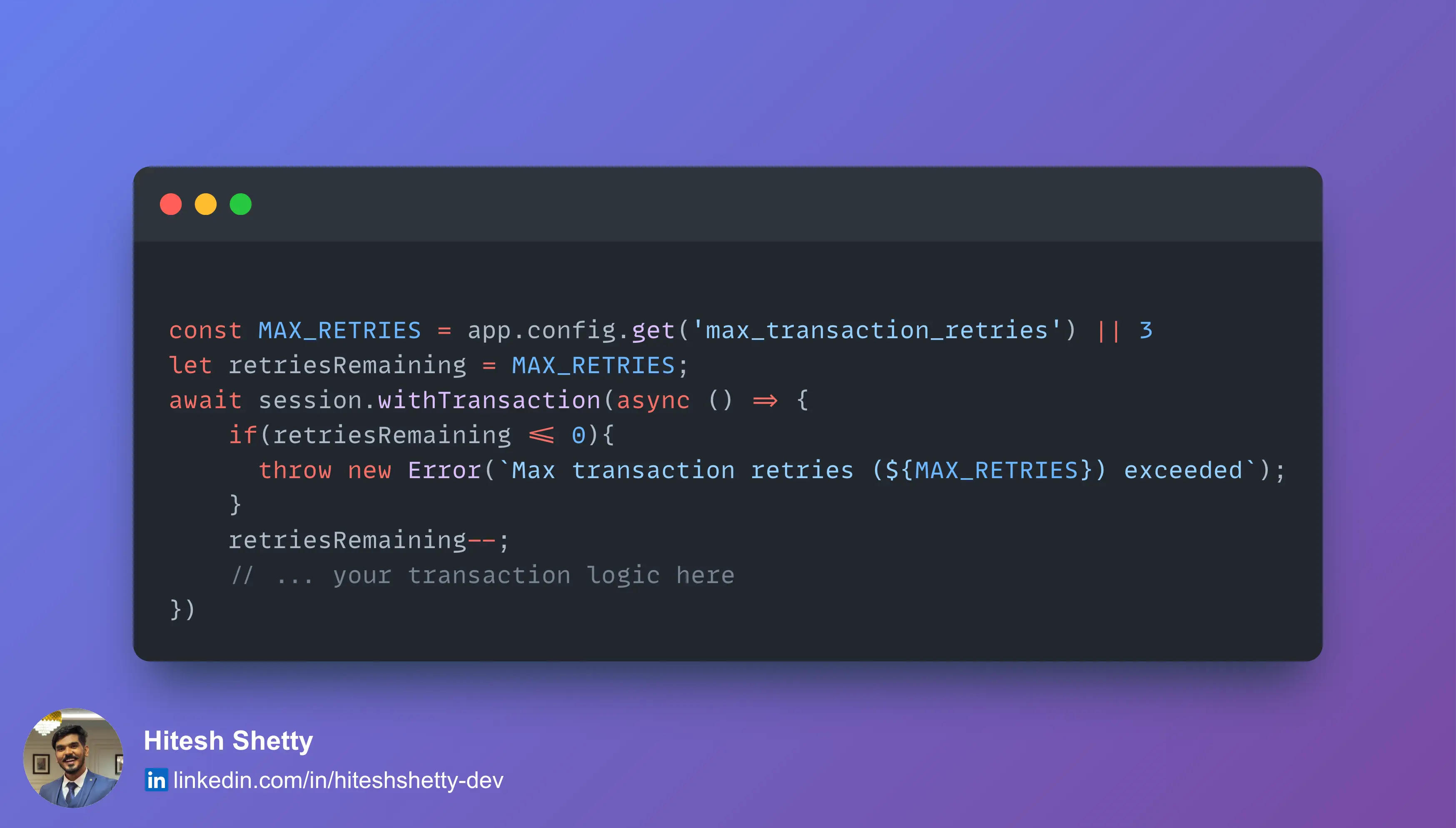
This stopped infinite loops and ensured transactions would eventually fail gracefully if retries were exhausted.
2. Reassigning Duplicate IDs
Before inserting content blocks, I reassigned new uids for duplicates blocks within API before insertion. Here’s the JSON RTE after the fix:
{
"entry": {
"title": "How to Debug Infinite Transactions",
"author": "Hitesh Shetty",
"publishedAt": "2025-09-20T10:00:00Z",
"content": {
"uid": "123",
"type": "doc",
"attrs": {},
"children": [
{ "uid": "456", "type": "paragraph", "text": "Transactions are great until they loop forever..." },
{ "uid": "790", "type": "paragraph", "text": "Load testing revealed unexpected behavior in my backend." }
]
}
}
}After applying these changes, CPU usage normalized, database connections stabilized, and POST requests completed reliably. Observability dashboards confirmed that backend performance issues were resolved.
Lessons Learned from Debugging Transactions
From this experience, I learned several crucial lessons for any backend engineer:
- Always set retry limits in production code.
- Load test with realistic and edge-case datasets (duplicate IDs, missing fields, etc.).
- Observability tools like Datadog are indispensable for tracing complex issues.
- Thoughtful transaction design can prevent cascading failures.
- Monitor for abnormal retry patterns to catch hidden performance bottlenecks early.
Designing Transactions with Safety in Mind
To prevent similar issues:
- Implement transaction retry policies.
- Include realistic load scenarios in automated testing.
- Set up monitoring and alerts for retry-heavy operations.
- Use defensive coding patterns in high-throughput, transaction-heavy systems.
Wrapping Up
What started as a mysterious CPU spike turned into a deep lesson in system design. By combining observability, realistic testing, and defensive coding, I was able to prevent an infinite retry loop from bringing down my backend.
For backend engineers and full-stack developers, this story isn’t just about fixing a bug, it’s about building resilient systems that scale gracefully, even under the most stressful load conditions.
Also available on Medium
This article is also published on Medium for interaction and feedback.